INTRODUCTION
In recent years, a rapidly increasing number of studies have begun to use healthcare claims database to assess healthcare intervention utilization patterns or outcomes [1]. Because observational studies using nationwide claims databases offer a large sample size with less strict inclusion and exclusion criteria than randomized controlled trials (RCTs), researchers may generate results more generalizable to realworld clinical settings.
The United States passed the 21st Century Cures Act in December 2016, with the goal of accelerating drug and medical device approval and promoting increased use of real-world data (RWD), including electronic health records, claims databases, registries, and healthcare applications, to generate real-world evidence (RWE) for potential risk and benefit assessments derived from sources other than RCTs [2]. In South Korea, revisions to the Personal Information Protection Act, the Act on Promotion of Information and Communications Network Utilization and Information Protection, and the Credit Information Use and Promotion Act were enacted in January 2020, and the Act on Safety and Support for Advanced Regenerative Medicine and Advanced Biopharmaceuticals will come into effect in August 2020. Based on growing needs to broaden access to healthcare information and generate RWE for the effectiveness and safety of clinical therapeutics, studies using RWD are expected to continue to increase in South Korea. However, methodological issues affecting study design or data analysis can make studies using healthcare claims databases challenging.
This review provides an overview of claims databases, describes some advantages and limitations of using claims data for research purposes, and presents steps for utilizing the Korean Health Insurance Review and Assessment (HIRA) and National Health Insurance Service (NHIS) databases. The study also reviews epidemiological approaches using healthcare claims databases in terms of protocol development, analysis, and reporting of results, and introduces guidelines and checklists including the Guidelines for Good Pharmacoepidemiology Practices (GPP), the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) checklist, and the Risk of Bias in Nonrandomized Studies of Interventions (ROBINS-I) tool.
NATURE OF HEALTHCARE CLAIMS DATABASES IN KOREA
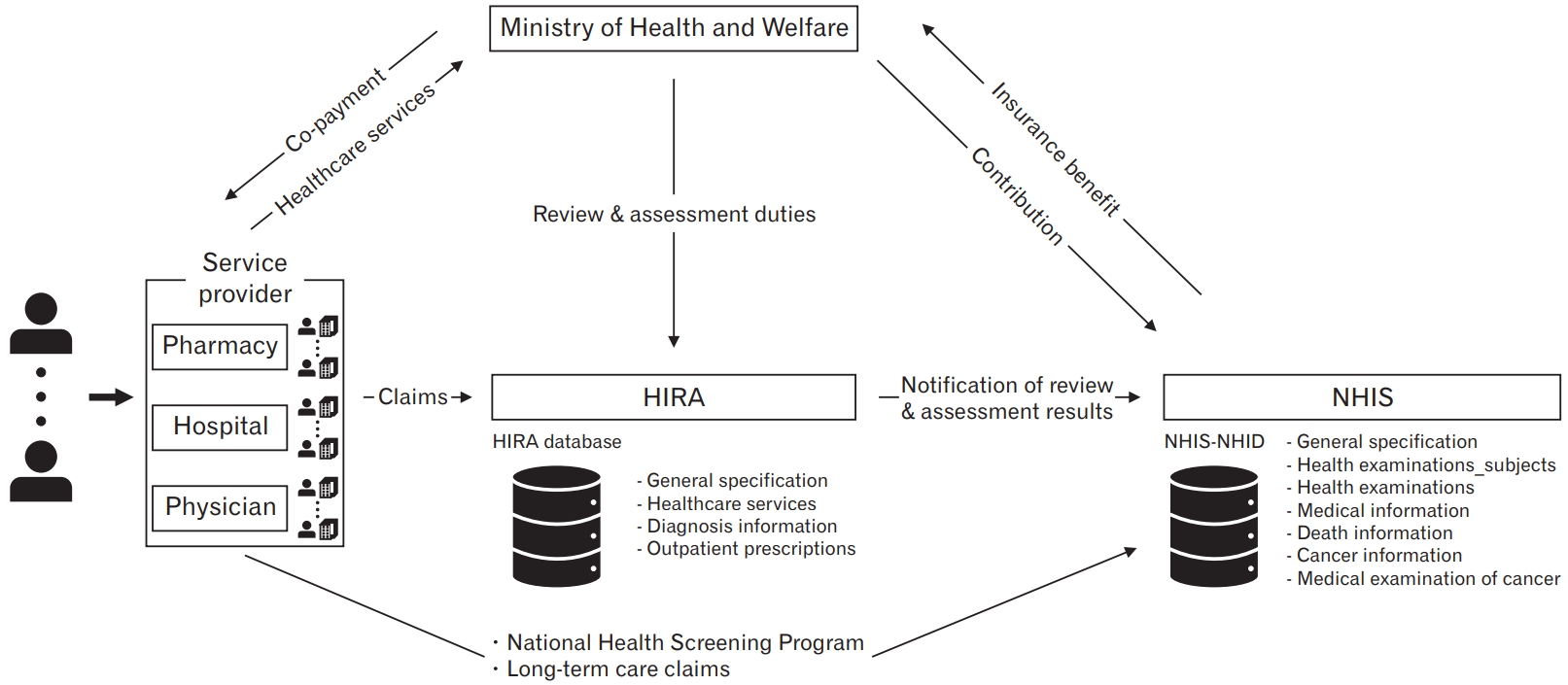
The South Korean health insurance system is a public, single-payer system. All citizens living in South Korea receive healthcare services as a fundamental right. Three major organizations are involved with the health insurance system: the Ministry of Health and Welfare (MoHW), the HIRA, and the NHIS. The MoHW operates and oversees the overall national health insurance system. Each individual (the insured) may receive a variety of medical services from service providers (healthcare institutions), which send reimbursement claims for medical expenses incurred to the HIRA. The HIRA reviews claims, assesses the quality of care provided, and evaluates healthcare services’ adequacy. Based on the results of the HIRA’s review, the NHIS reimburses services providers for medical care services provided. Throughout the process, all data related to medical services are accumulated in both HIRA and NHIS databases (Figure 1).
In recent years, various studies using data from the NHIS and HIRA have become possible under the Act on Promotion of the Provision and Use of Public Data. However, because these databases are intended for administrative and not research purposes, the data must be processed before they can be used for research. Therefore, it is necessary for clinical researchers to fully understand the structure of each database.
Both databases are multi-layer in structure. If a patient is provided with medical services multiple times, multiple claims are generated, each of which contains information such as procedures performed, medications taken, and so on. Additionally, single claims are divided into several tables: specifications, treatment details, disease details, and prescription. Each table can be conjoined through a claim’s key sequence number. Specifications (designated “Table 20”) includes general information regarding the treatment, such as primary/secondary diagnosis, date of visit, and length of treatment in days. Treatment details (designated “Table 30”) contains procedure codes, treatment codes, and prescription drugs for inpatients. Disease details (designated “Table 40”) include all diagnosis codes pertaining to the patient. Finally, prescription (designated “Table 60” in the NHIS database and “Table 53” in the HIRA database) contains information on medications, such as generic medication codes, daily doses, unit doses, and days of supply for outpatients. Both the NHIS and HIRA databases include their own specific tables in addition to these general medical treatment-related [3-7].
CURRENT STATUS OF HEALTHCARE CLAIMS DATABASES AND OTHER HEALTHCARE BIG DATA IN SOUTH KOREA
In South Korea, health insurance is a single-payer system managed by the HIRA and NHIS [8]. The government-run national healthcare claims databases cover approximately 98% of the total population and are available to researchers for public research purposes (Table 1).
The HIRA maintains a claims database for all patients, known as the HIRA database, along with four types of sampling databases with information from 2009 to 2018: the HIRA-National Patient Sample, HIRA-National Inpatient Sample, HIRA-Aged Population Sample (HIRA-APS), and HIRA-Pediatric Patient Sample [9]. The samples are updated annually and extracted using demographic stratification of age and gender [10]. Researchers can apply to use these claims data online (https://opendata.hira.or.kr/home.do).
The NHIS also maintains a database for the whole population of South Korea, the NHIS-National Health Information Database, and several sampling cohort databases: the NHIS-National Sample Cohort (NHIS-NSC), NHIS-National Health Screening Cohort (NHIS-HEALS), NHIS-senior cohort, NHIS-Female Employees (NHIS-FEM), and NHIS-Infants and Children’s Health Screening (NHIS-INCHS). The NHIS-NSC includes a stratified random sample for age, gender, participant’s eligibility status, region, and income level based on Korean population in 2006 [5]. The NHIS-HEALS, NHIS-senior cohort, and NHIS-FEM are simple random samples of individuals [11,12]. The NHIS-INCHS was extracted from 2008–2012 births and samples 5% of the population by birth year. Researchers can access the NHIS databases and their information online (https://nhiss.nhis.or.kr/bd/ay/bdaya001iv.do).
The two claims databases appear similar, but have several important differences. First, the two institutions include slightly different variables in their datasets. The HIRA research database’s main sections include patients’ general specifications, healthcare utilization, diagnoses, and outpatient prescriptions (Table 2) [9,13]. The NHIS database’s main sections include healthcare utilization, sociodemographic variables, health screening, and mortality [14]. Second, the HIRA sample databases include separate cohorts for each year, whereas the NHIS sample databases include longitudinal cohorts [5,9]. Because patients are stratified and resampled annually in the HIRA sample databases, patient information in cannot be linked across years within HIRA sample databases. Therefore, the HIRA sample database is useful for conducting cross-sectional study or short-term follow-up (less than 1 year) studies. In contrast, participants in the NHIS sample cohort databases can be followed for up to 13 years. For example, researchers can assess exposure status during 2002 and follow up until the incidence of the study outcome or the end of the study period in 2015. Therefore, the NHIS sample cohort database is appropriate for study hypotheses requiring long-term follow-up.
In response to recent emphasis on the importance of big data, the Healthcare Big Data Platform has been established, which can link to claims databases. Linkable databases include the Korea National Cancer Incidence database provided by the National Cancer Center, the Korea National Health and Nutrition Examination Survey database, the Quarantine database, the Korean Tuberculosis Surveillance System database, the Korean Genome and Epidemiology Study database, and immunization registry data provided by the Korea Centers for Disease Control and Prevention [15-17]. All databases can be linked to each other, accessed online via the Healthcare Big Data Platform (https://hcdl.mohw.go.kr/BD/Portal/Enterprise/DefaultPage.bzr).
APPLICABILITY OF HEALTHCARE CLAIMS DATABASES
Healthcare claims databases are useful for clinical epidemiological research, particularly medication research on prescribing patterns, medication adherence, and adverse drug events [18]. Among observational research studies of clinical outcomes, analytical study designs can be roughly divided into cross-sectional studies, case-control studies, and cohort studies. A cross-sectional study measures both exposure and outcome at the same time; a case-control study first measures outcome, then determines any previous exposure; and a cohort study classifies groups according to exposure and follows up to confirm the outcome [19]. Recently, a number of observational studies using healthcare claims databases have been reported in Korea. This section considers examples of such studies by design.
An example cross-sectional study used a HIRA-APS dataset (stratified proportional sample of patients over the age of 65 years) to assess medication use among elderly patients in intensive care units [20]. Using this dataset, the researchers analyzed patterns of medication use in real-world settings according to duration of mechanical ventilation, patient age, and annual trends, and assessed patient factors related to the use of sedatives and analgesics in elderly patients.
An example nested case-control study examined the risk of esophageal or gastric cancer after exposure to oral bisphosphonates in the Korean population using the NHIS-NSC database [21]. From a cohort of over 160,000 patients with osteoporosis, 1,708 cases were selected (patients aged 40 years and above with initial esophageal or gastric cancer). For each case, four controls were matched for age, gender, and income level. The study did not confirm a significant association between bisphosphonates and upper gastrointestinal cancer in realworld settings.
An example cohort study was conducted using the NHIS-HEALS, a database constructed using the NHIS claims database and the national health screening databases [22]. The study estimated the association between various risk factors (e.g., body mass index and health-related behaviors such as smoking and alcohol consumption) and dementia using a Cox proportional-hazards model. Because this dataset provided health screening data biennially for each individual, weight change could be identified [11]. The study found that both weight gain and weight loss are potential risk factors for dementia, and therefore that weight changes should be carefully monitored.
ADVANTAGES AND LIMITATIONS OF USING HEALTHCARE CLAIMS DATABASES FOR RESEARCH
Healthcare claims databases offer several important advantages for research (Table 3). First, because almost all Korean populations are covered by national insurance, research results are highly generalizable [23]. Second, because claims databases are constructed during the course of medical services, and are thus not dependent on the memory of patients or healthcare professionals, recall bias is minimized. Third, they cover disease conditions thoroughly utilizing international disease code classifications. Fourth, the databases have sufficiently large sample sizes to retain statistical power, and contain various information on healthcare utilization, diagnoses, procedures, treatment, and payments. Fifth, use of a healthcare database is relatively quick and inexpensive compared to implementation of a clinical trial. Finally, these databases can be linked to various others, including the Korea National Cancer Incidence database and information on mortality (date and cause of death) from Statistics Korea. For example, a study has assessed the association between fatal motor vehicle collisions and zolpidem prescription by linking the database of the Korea Road Traffic Authority with health insurance data from the NHIS [24].
However, research using healthcare databases is also subject to certain limitations. First, confounding biases may be introduced. Confounding by indication results when the patient’s condition for which the drug is prescribed is itself is related to the outcome. For example, a study of the association of suicide and selective serotonin reuptake inhibitors (SSRIs) may be vulnerable to confounding by indication because SSRIs are indicated to treat depression, which may cause suicidal ideation. This could lead to erroneous conclusions or overestimation of the strength of any association [25]; confounding by indication may thus bias the relative risk of adverse events away from the null. A healthy user effect, in which receiving treatment is associated with underlying patient characteristics like high education level and attitude to pursue health [26,27], may also distort interpretation of the results. For instance, observational studies of hormone replacement therapy (HRT) have shown that women who took HRT tended to demonstrate more healthy behaviors, such as regular exercise and healthy diet, compared to the nontreatment group; the apparent protective effect of HRT against cardiovascular disease appears to reflect these differences in patients’ underlying characteristics [26]. Additionally, unmeasurable potential confounders such as laboratory data, disease severity, or patient-reported outcomes prevent complete control of confounding effects [27]. For example, although the databases contain a diagnosis code for cancer, they do not record information on the stage or severity of the disease. Second, misclassification bias can occur when defining both exposure and outcome variables [28]. Due to insurance reimbursement policies and the fee-for-service system, up-coding issues may arise, and discrepancies between diagnosis coding and patients’ actual health conditions may exist. A previous study reported only 70% accuracy of diagnoses in claims databases [29]. Third, because the purpose of claims databases is to reimburse healthcare services, they are not applicable to research on healthcare services not covered by insurance or over-the-counter drugs. Fourth, it is impossible to accurately measure medication adherence using claims data; prescription of a drug does not mean that the patient actually took the drug. Fifth, there is a time gap between the time health services are actually provided and the time a claim for the service becomes available for research [30]. Finally, diseases with low prevalence may be difficult to study using HIRA or NHIS sample databases because of small sample sizes and lack of representativeness to the target population.
GUIDELINES FOR CONDUCTING AND REPORTING OBSERVATIONAL STUDIES USING HEALTHCARE CLAIMS DATABASES
Several methodological criteria and checklists for conducting and reporting observational studies using the healthcare claims database have been developed (Table 4). The Guide on Methodological Standards in Pharmacoepidemiology version 7, published in 2018 by the European Network of Centres for Pharmacoepidemiology and Pharmacovigilance, addresses the overall steps for conducting a pharmacoepidemiological study, from formulating research questions to addressing ethical issues and communicating study results to ensure scientifically independent and transparent research. Researchers can refer to the related checklist for study protocols, developed based on the criteria in this guideline, to consider and be aware of key epidemiological principles.
The GPP version 4, developed by the Public Policy Committee and International Society of Pharmacoepidemiology in 2016 [31], suggests essential principles to consider as check points to ensure methodological quality when conducting and evaluating pharmacoepidemiologic studies. The checklists include definitions of exposures, outcomes, other risk factors, statistical precision, data management and analysis, and quality control.
The STROBE Initiative’s established recommendations for conducting observational research [32], the STROBE Statement, was updated up to revision 4 in 2007 and presents checklists for researchers according to study design. Because the STROBE Statement’s aim is to improve the quality of observational research reporting, the checklist items pertain to procedures for reporting research in papers, such as the title and abstract, introduction, methods, results, and discussion sections.
The Cochrane Bias Methods Group developed an evaluation tool, the ROBINS-I, to assess the risk of bias in nonrandomized studies in 2016, using criteria for RCTs [33]. The tool focuses on internal validity and utilizes a hypothetical ideal target trial. It is designed for use in observational studies and assesses seven bias domains: selection of participants, confounding, classification of interventions, missing data, deviations from the interventions, selection of reporting results, and measurement of outcomes.
CONCLUSION
Korean national health insurance claims databases are a useful source of data for generating RWEs with high generalizability in the Korean population. However, these databases also have inherent limitations, including confounding bias, selection bias, and validity of study variables. Therefore, clinical research studies using and reporting results based on Korean healthcare insurance claims databases must be well designed, with rigorous analysis and careful interpretation considering the risks of bias.